The most accurate LinkedIn post previewer

Pierce Freeman
October 4, 2024
You know the old saying "you have only 15 minutes to impress someone?" On social media feeds it's more like 500 milliseconds. That's how long it takes for someone to decide whether to engage with your post or keep scrolling.
So how do you make sure your LinkedIn posts are engaging enough to stop the scroll? You need to create content that immediately grabs their attention. My co-founder Will has a lot more thoughts on how to write effective hooks, from his experience growing to 370k+ followers in 15 months.
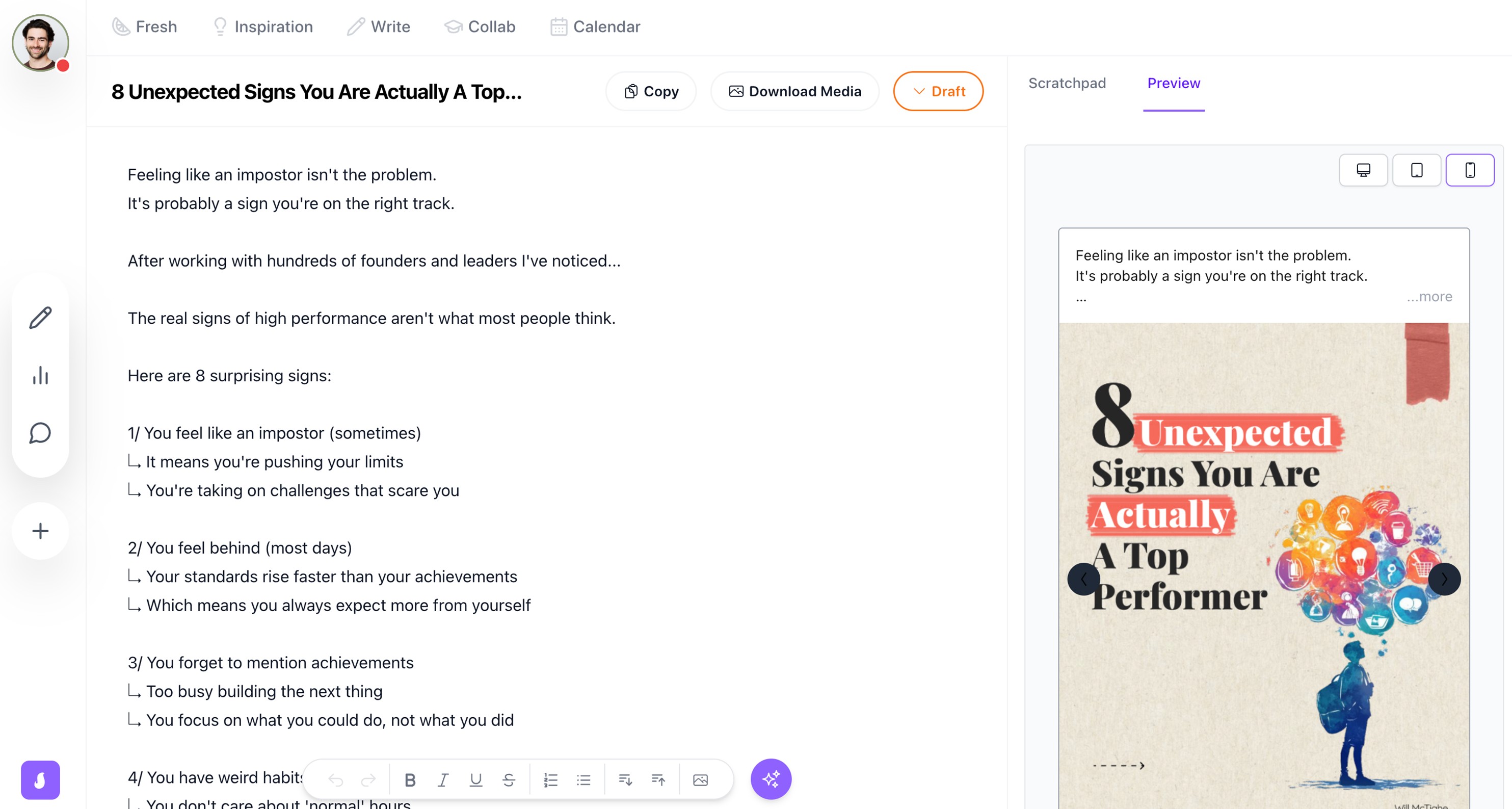
But once you have an amazing hook, how do you actually make sure users see it? People engage with LinkedIn across a host of devices. The numbers were split roughly down the middle in 2024: 57% of users come from mobile and the rest browse on desktop. This stands in contrast to most other social media platforms, where mobile usage is much higher. Optimizing your content for both mobile and desktop is crucial.
Different devices affect your hook's appearance. Words will break differently on a mobile screen than a desktop, fonts might vary, etc. What looks perfect in editing might look like a mess on another platform. That's why it's important to preview your post on both mobile and desktop before you hit publish. But how can you do that without actually posting it?
At Saywhat, I can confidently say we've built the most accurate LinkedIn post simulator on the market. Here's how we did it. Nerdy details ahead! If you just want to try it out for yourself, sign up for a 7-day free trial of Saywhat's AI writing assistant.
Getting the data

Our goal is to simulate LinkedIn to the pixel. So naturally the best place to start is LinkedIn itself. By scrolling through the newsfeed across a range of devices, we collected thousands of different screenshots of how posts look in practice. This captures all the richness: the text itself but also the spacing, the font size, the line breaks, and the "see more" button.
We capture the preview view, full view, and the raw original text of the post for good measure. We want all of them to align with expectations.
Once we collected the images, we could feed it into an OCR (optical-character-recognition) pipeline to extract the text that's contained within the screenshot. Unlike a typical OCR task for documents, where you want to transcribe everything, our use case here is a bit different. We're only interested in the post body of the main post on the screen - not the author details, other posts, or navigation body. This is a bit tricky because the OCR model doesn't know what's important and what's not. Instead, a visual-aware LLM is actually a much better fit for this task.
You can get pretty close with a prompt like this:
Transcribe the text from a social media post exactly line by line, preserving linebreaks.
## Steps
- Read the main social media post presented on the screen. Only focus on the primary post, not any other posts.
- Identify and transcribe each line of visible text exactly as it appears.
- Preserve the original linebreaks in your transcription.
## Output Format
- A plain text format retaining all linebreaks and specific instructions like [see more].
Examples
## Example Input:
Social Media Post displayed on screen.
## Example Output:
This is the first line of the post. This is the second line. This line might get cut with a ...see more
The output of this pipeline is a single text file for every screenshot that we collected. Raw output from the model looks like this:
Something that has been on my mind lately is AI. It's
everywhere and in every product these days, but let's be
honest, it's not always great. ...see more
Simulating the linebreaks
Linebreaks are the first challenge we have. How does LinkedIn decide where to break the line? It obviously depends on the screen size, but is there more to it? And how exactly can we find the right value?
Now that we have our screenshots of how we want the content to look, we can setup an html view that replicates the styling that you'll find on your newsfeed. Since html is inspectable, we can see the exact styling that LinkedIn is using. We can then use this information to reproduce the newsfeed in an html context that we control.


Once we recreate an interactive news feed widget, our challenge becomes figuring out how different screens will interact with the page. On first blush this seems easy - just render the original text within our controlled widget and see where the line breaks happen. In the screenshot above we can clearly see that's:
emission
building's
exceeding
This certainly works when we're inspecting it visually. But when dealing with our thousands of datapoints we need an automated way to model the visual rendering. And html doesn't have support for programmatically determining the location of linebreaks in rendered text. From the perspective of Javascript in your browser, text is just one long line. It's the visual renderer (Chromium, Webkit, etc) that determines where to break the element at the last mile.
However - there's a workaround. If we insert the elements character-by-character, we actually can determine the position of the these characters through the help of window.getComputedStyle. This will show us the bounding box of each character's coordinates.

We can use the y-coordinate of the characters to determine when we've broken the line. This gives us what we're hoping for, a Javascript payload of the linebreaks that will show up visually when LI is rendered on different device sizes.
{
"lines": [
"Penalties are becoming more severe",
"for landlords not meeting building"
]
}
Automating our search
We want to find what viewport widths produce the linebreaks that we've transcribed via OCR. We built a simulation interface that allows us to provide the original text and the text that we expect to find. It does a sweep of all viewport widths (including fractional pixels) and maximum word rules to determine the parameters that will make our posts look the same as they will when posted on LinkedIn.

We then boot up a fleet of virtual browsers to perform this sweep in parallel, and extract the raw results for postprocessing.
async def process_file(page, filename, raw_content, content):
# Postprocessing of gpt-data
raw_content = strip_gpt_artifacts(raw_content)
content = strip_gpt_artifacts(content)
extracted_raw = get_input_from_raw(content, raw_content)
url = f"file:///Users/piercefreeman/projects/li-linebreaks/linewraps.html"
await page.goto(url)
await page.get_by_test_id('rawInput').fill(extracted_raw)
await page.get_by_test_id('expectedOutput').fill(content)
await page.click("text=Detect line breaks")
try:
await page.wait_for_function(
"() => document.querySelector('#progressBar').textContent === '100%'",
timeout=45000
)
except TimeoutError:
logging.warning(f"Timeout occurred for file: {filename}")
return None
logging.info("Finished rendering...")
valid_line_breaks = await page.evaluate("window.validLineBreaks")
return valid_line_breaks
Conclusion
When our full sweep is completed, we land on the perfect parameters for desktop, tablets, and mobile views. With the thousands of examples worth of evidence we can test the Saywhat post previewer comprehensively. This guarantees that your hooks will look as good at post time as they will during writing time.
Did I mention that we also have a full writing suite that dramatically decreases the time to write viral content? That's a subject for another day.
Start building your personal brand today.
Join top executives and creators in using our AI-powered writing, community, and lead gen tools to scale your LinkedIn business.